Przejście z relacyjnych bazy danych do świata NoSQL nie jest łatwe. Dosłownie wszystko jest inne, co czasami może przytłaczać, aż do tego stopnia, że nie wiadomo jak rozwiązać problem tak trywialny, że praktycznie nieistniejący w świecie SQLa.
Dziś o takim problemie chce Ci opowiedzieć. Wyobraź sobie, że w swojej relacyjnej bazie danych przechowujesz w tabeli rekordy zamówień. I potrzebujesz informacji o ostatnim (najnowszym) numerze zamówienia. (Po co to już osobny temat.)
Ostatni numer zamówienia w SQL
W SQLu problem jest tak prosty do rozwiązania, że aż trywialny. Wystarczy napisać:
1 | SELECT orderId FROM Orders ORDER BY orderId DESC LIMIT 1; |
Nie dość, że zapytanie jest proste to i bardzo wydajne (szczególnie gdy mamy indeksy). Brawo dla SQLa 👏
Ostatni numer zamówienia w DynamoDB
I tutaj zaczynają się schody. Nie podam Ci od razu rozwiązania, gdyż do pełnego zrozumienia wymaga ono pewnej wiedzy na temat tego, jak DynamoDB jest zbudowane i dlaczego pewne sposoby pracy z nim są niepożądane.
Trochę teorii o DynamoDB
Zacznijmy od tego, że odpowiednikiem SQLowego SELECT w DynamoDB są dwa polecenia scan i query. Oba służą do pobierania informacji z tabeli (w DynamoDB mamy tylko koncept tabeli, a nie całej bazy danych). Jednak różnią się one znamiennie od siebie. Metoda scan skanuje zawartość całej tabeli i zwraca ją nam w postaci kolekcji elementów.
Dla poniższej tabeli scan by zwrócił 6 elementów bo mamy sześć zamówień.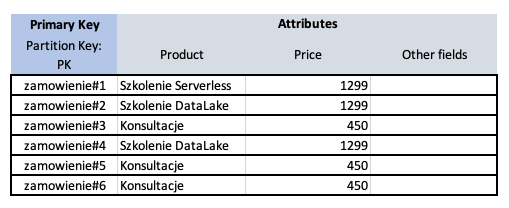
Korzystając ze scan moglibyśmy pobrać informacje o wszystkich zamówieniach i po stronie kodu np. w funkcji Lambda, przefiltrować dane i wybrać najnowszy (ostatni) numer zamówienia.
Takie podejście jest oczywiście najgorszym możliwym, gdyż pobieramy z bazy dużo więcej danych niż chcemy (kolekcja zamówień vs pojedynczy numer zamówienia). To wpłynie na czas działania naszej aplikacji, ale też na koszty, gdyż w DynamoDB płacimy za każde zapytanie / ilość danych zwróconych. Na domiar złego, w przypadku dużej ilości danych dochodzi jeszcze page’owanie wyników.
Rozważmy zatem inne opcje.
Metoda query służy do pobierania danych z kolekcji lokalnej, czyli elementów w bazie, które mają wspólny (ta sama wartość) klucz Partition Key.
Staram się, aby ten artykuł był zwięzły oraz spójny, dlatego nie zamierzam tutaj omawiać budowy DynamoDB. Natomiast bardzo Cię zachęcam do poznania jej na własną rękę, gdyż to po prostu dobra szkoła architektoniczna i pomoże Ci w zrozumieniu, dlaczego z tej bazy danych korzysta się w taki, a nie inny sposób.
W naszej tabeli z zamówieniami (powyżej) każde zamówienie ma inną wartość Partition Key, dlatego użycie metody query po prostu nie ma tutaj sensu, gdyż nie mamy kolekcji lokalnych.
Na marginesie, przykładem kolekcji lokalnej do zamówienia mogłaby być lista towarów w zamówieniu. W takim wypadku każdy klucz główny elementu Primary Key by się składał z dwóch wartości (klucz kompozytowy):
- Partition Key
- Sort Key
Tabela by się zmieniała jak na poniższym przykładzie, wtedy wywołanie query z parametrem zamowienie#2 zwróci nam dwa elementy, ponieważ w tym zamówieniu ktoś kupił dwa produkty: Szkolenie DataLake i Konsultacje.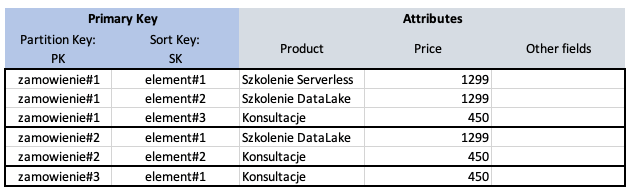
To jest jednak inna strategia dostępu do danych w DynamoDB i tylko przy okazji ją tutaj Tobie przedstawiłem.
Zatem, co możemy zrobić skoro ani scan ani query się nie nadają, aby zwrócić ostatni / najnowszy numer zamówienia?
Metoda GetItem
Istnieje jeszcze GetItem, metoda która zwraca nam pojedynczy element z bazy po podaniu konkretnej wartości Primary Key. To takie getById(id) lub SQLowe:
1 | SELECT * FROM Orders WHERE orderId = 'numerZamowienia'; |
Wszystko pięknie, tylko skąd mamy wziąć ten numerZamowienia skoro właśnie jego chcemy z bazy wyciągnąć? 🤔
Strategia wskaźnika
W tym miejscu właśnie pojawia się tytułowa strategia wskaźnika.
Wartość nieznaną możemy zastąpić czymś z góry znanym, pewną stałą i przez nią się odwoływać do bazy. Ten element o stałym Partition Key będzie tylko jeden w całej tabeli i dlatego będziemy go mogli wykorzystać jako wskaźnik do przechowywania wartości najnowszego zamówienia.
Do naszej pierwszej tabeli, dodajemy kolejny element o Partition Key wynoszącym zawsze LAST_ORDER (nasza stała). Taki element ma jeden atrybut o nazwie OrderId z wartością najnowszego zamówienia. Za każdym razem, gdy dodajemy do tabeli nowe zamówienie, aktualizujemy również wartość elementu LAST_ORDER na wartość nowego zamówienia.
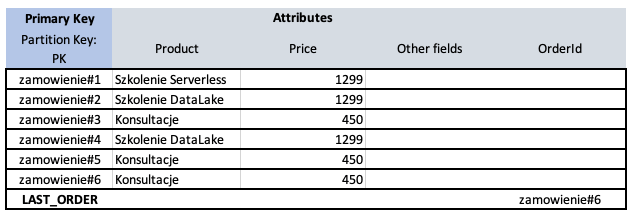
Natomiast na poziomie zapytania, wywołujemy proste getItem('LAST_ORDER'), które zwraca nam w optymalny sposób największy numer zamówienia.
Zaawansowane techniki
Biorąc pod uwagę, że tabela DynamoDB raczej nie istnieje sama dla siebie i jest zwykle częścią większego systemu zastanówmy się, co się stanie, gdy do bazy zapisuje równolegle wiele procesów (bezpośrednio lub przez kolejkę SQS - bez różnicy). Na pewno zdarzy się sytuacja, że ostatnio zapisany element do bazy, wcale nie będzie najnowszym (ostatnim) zamówieniem. Wówczas wskaźnik LAST_ORDER będzie błędnie wskazywał na starsze zamówienie.
Ten problem moglibyśmy rozwiązać przez zastosowanie kolejki SQS FIFO, ale jest na to dużo prostsze i tańsze rozwiązanie.
Wystarczy, że zastosujemy wyrażenie warunkowe ConditionExpression przy zapisie nowej wersji elementu LAST_ORDER, które sprawdzi, czy nowa wartość orderId jest większa od obecnie zapisanej w bazie. Jeśli jest to zaktualizuje, jeśli nie to nie.
Dzięki temu, posługując się jednym zapisem do bazy, możemy zaktualizować wartość bez jej uprzedniego pobierania i sprawdzania po stronie kodu. Dodatkowo jest to metoda idempotentna (w przypadku gdy dostaniemy wielokrotnie ten sam event, nie zmieni stanu bazy przy kolejnych wywołaniach).
Jak to zrobić?
Pora na trochę kodu. Przykładowa implementacja w JavaScript wygląda następująco:
1 | async createPointer(orderId) { |
Omówienie kodu:
- Linijka 4 - klasa Pointer implementuje metodę, ktora zamienia obiekt
Pointerna JSONa, którego oczekuje API DynamoDB. Poniżej implementacja tej metody. - Linijka 7 - wyrażenie warunkowe: kiedy zapisać do bazy, a kiedy nie?
attribute_not_exists(#orderId)jest potrzebne, aby przy pustej bazie kod też się wykonał i po raz pierwszy zapisał element. Od tego momentu tylko drugi człon#orderId < :newIdwarunku będzie miał znaczenie. - Linijka 19 - jeśli warunek nie został spełniony, to API DynamoDB zwraca wyjątek
ConditionalCheckFailedException, który w naszym wypadku jest prędzej czy później oczekiwany.
A tutaj obiecana implementacja klasy Pointer.
1 | class Pointer { |
Uwaga, styl tej klasy jest bezczelnie zerżnięty od Alexa DeBrie 😃
Jeśli jesteś zapisany(na) do mojego newslettera Serverless Polska to na pewno wiesz, że wielokrotnie pisałem o nim i jego książce The DynamoDB Book. To najlepsza pozycja na rynku do nauki tej bazy jaka istnieje!
Jeśli nie czytasz mojego newslettera to możesz się zapisać tutaj - gorąco Cię do tego zachęcam!
Poza cotygodniową dawką informacji na temat serverless i AWS, otrzymasz zawsze najlepsze oferty na materiały do nauki. Przykładowo, dla czytelników Serverless Polska załatwiłem kupon zniżkowy na książkę Alexa. Przy zamówieniu, w pole Discount code wpisz serverlesspolska. Uwaga: to nie akcja afiliacyjna - nic na tym nie zarabiam, polecam z czystym ❤️ bo to niespotykanie dobra książka, która nauczyła mnie jak korzystać z DynamoDB.
Podsumowanie
Mam nadzieję, że ten uproszczony, ale wzięty z mojego rzeczywistego systemu, przykład pomógł Ci zrozumieć zawiłości korzystania z DynamoDB. Omówiłem tylko mały obszar wiedzy, ale równocześnie pokazałem, jak rozwiązać konkretny problem, który możesz napotkać w swoich projektach.
Mam świadomość, że próg wejścia w DynamoDB jest wysoki - nie ma co tego ukrywać - ale szczerze, nie wyobrażam sobie systemów serverless bez bazy DynamoDB. W 9 na 10 przypadków wybiorę właśnie DynamoDB ponad AWS RDS (wliczając w to Aurorę Serverless).