Nowe rozwiązanie starego problemu
Jestem pewien, że dokładnie wiesz, jak trudno jest okiełznać dane, zwłaszcza że w wielu przypadkach mamy do czynienia z przyrostem wykładniczym. Dosłownie wszystko może nieść ze sobą bezcenne informacje na temat tego, co można usprawnić w każdym aspekcie prowadzenia biznesu. Jednak w miarę upływu czasu wielkość i ilość tych wszystkich źródeł, katalogów i miejsc staje się przytłaczająca. A to wszystko utrudnia przetwarzanie danych.
Wszyscy intuicyjnie (a niektórzy wiedzą to z doświadczenia), że zbieranie danych bez określonego celu to sztuka dla sztuki. Przygotowanie strategii dotyczącej danych to pierwszy krok, ale co dalej? Przytłaczająca ilość źródeł nie pomaga. A my przecież potrzebujemy nie tylko surowych danych, ale tych przetworzonych, żeby usprawniać biznes i nadążać za konkurencją.
Najprostszym sposobem zaadresowania tego problemu jest zastosowanie dobrze znanych technik — ten problem istnieje od dawna. Wiele lat temu opracowano rozwiązania tego problemu w postaci hurtowni danych. Wybierając takie rozwiązanie i agregując nasze dane w zgodzie z podejściem OLAP (skrót od Online Analytical Processing) możemy korzystać z wielu lat doświadczeń i sprawdzonych rozwiązań.
Jest tylko jeden problem: taka hurtownia danych coraz częściej okazuje się zbyt statyczna. W dzisiejszym świecie to dla wielu biznesów niewystarczające podejście.
Co więcej, w takich zastanych rozwiązaniach mamy dodatkowo do czynienia z:
- silosami, gdzie dane są uwięzione i odizolowane od innych, przez co nie możemy ich przeanalizować w szerszym kontekście,
- opóźnionymi danymi, bo dane docierają zbyt późno i nie mogą pomóc przy wyciąganiu dodatkowych wniosków oraz przy budowaniu przewagi,
- drożyzną, bo koszty przeprowadzenia analizy i utrzymania przewyższają potencjalne zyski z wyciąganych wniosków,
- złożonością, która pozwala na działanie i uruchomienie platformy, ale tylko kilka osób potrafi ją efektywnie wykorzystać,
- ekskluzywnością, sytuacja związana z powyższym punktem, co nie pozwala na demokratyzację w wykorzystaniu danych i budowania kultury podejmowania decyzji na podstawie danych.
Mając to wszystko na uwadze, zastanawiasz się, jak Twój biznes może zbierać, przechowywać, i analizować dane w czasie rzeczywistym, tak aby dobrze sobie radzić na konkurencyjnym rynku. Wszystkie wspomniane wyzwania, świetnie adresuje architektura oparta o jezioro danych (ang. data lake).
Czym jest jezioro danych?
Jeśli to zupełnie nowy termin dla Ciebie, polecam Ci przeczytać poprzedni post, który wyjaśnia to pojęcie. Zaraz potem zapraszam do dalszej lektury.
Jeśli już wiesz, o czym mowa — porozmawiajmy o tym, co daje nam to podejście.
Jaką wartość niesie ze sobą to rozwiązanie?
Na pierwszy rzut oka, całość może wyglądać na niepotrzebną komplikację w postaci czarnej dziury wciągającej Twoje dane. Dlaczego chcielibyśmy składować wszystkie dane, najlepiej w surowej postaci, w jednym miejscu?
Okazuje się, że firmy, wykorzystujące to podejście z sukcesem wyciągają wnioski z prowadzenia biznesu i osiągają znacznie lepsze wyniki niż ich konkurencja. Potwierdza to badanie firmy Aberdeen, które pokazuje, że firmy, które wykorzystują jeziora danych, przewyższają swoją konkurencję z tego samego sektora o 9%, w kwestii organicznego wzrostu przychodów.
Tacy liderzy są w stanie skorzystać z nowych typów analityki oraz uczenia maszynowego, zaprzęgając do tego nowe źródła danych takie jak logi aplikacyjne, dane z operacji użytkowników, dane pochodzące z mediów społecznościowych, oraz urządzeń podłączonych do internetu. Dzięki temu mogą szybciej zidentyfikować nowe trendy i odpowiednio zareagować na szanse, które pomagają im rozwinąć ich biznes przez przyciągnięcie i utrzymanie nowych klientów, podnoszenie produktywności, lub proaktywne utrzymanie maszyn — mówiąc bardziej ogólnie: za pomocą szybkich i świadomie podejmowanych decyzji.
Jak wspomniałem wyżej, ponieważ taka architektura pozwala na składowanie surowych danych w jednym miejscu, a dodatkowo mamy możliwość w zasadzie dowolnej zmiany formatu, znacznie łatwiej jest korzystać z analityki oraz uczenia maszynowego. Jest to efektywniejsze podejście niż w tradycyjnym, opartym o silosy, podejściu. Dodatkowo dzięki tej architekturze, wielu interesariuszy w ramach Twojej organizacji może korzystać z analizy danych pochodzącego z jedynego i kompletnego źródła prawdy. Dzięki temu jesteśmy w stanie burzyć mury oraz podziały w danej organizacji. Warto nadmienić, że tak powstają innowacje, bo mając tak przekrojowe dane, możemy szybciej wyciągać wnioski i lepiej reagować. Takie działania napędzają koło zamachowe innowacji w Twojej firmie.
Przykłady zastosowań
Porozmawiajmy zatem o konkretnych przykładach. Na pierwszy ogień pójdzie firma Zillow z branży nieruchomości, która zbudowała jezioro danych na podstawie usługi Amazon S3, w którym przetrzymuje petabajty danych. Do analizy danych wykorzystują oni usługi z portfolio AWS — takie jak Amazon EMR oraz Amazon Kinesis — a to wszystko w celu personalizacji i optymalizacji reklam oraz ofert, dla ponad 100 000 mieszkań i domów.
Innym świetnym przykładem jest organizacja Finra, która wykorzystuje Amazon S3 jako fundament jeziora danych oraz usługę Amazon EMR, w celu walki z oszustwami, manipulacją, wykorzystaniem poufnych informacji (ang. insider trading), oraz z innymi nadużyciami. Koszty nowej architektury w porównaniu do poprzedniej lokalnej infrastruktury zmalały o 60%, co potwierdza poniższa analiza.
Jeśli dalej Cię nie przekonałem, zwróć uwagę na firmę Redfin, gdzie wykorzystanie jeziora danych pozwoliło na szybkie i opłacalne wdrożenie innowacji dotyczących zarządzania portfolio dla milionów nieruchomości. I na koniec, Nasdaq, który wykorzystał to podejście do optymalizacji wydajności, dostępności, i bezpieczeństwa przy ładowaniu oraz przetwarzaniu 7 miliardów wierszy danych dziennie.
Jak zatem AWS może Ci w tym pomóc?
Jako dostawca, AWS dostarcza najbardziej kompletne, bezpieczne, i opłacalne portfolio usług do każdego etapu, jeśli chodzi o budowę rozwiązań związanych z analizą danych oraz opartych o architekturę data lake. Znajdziemy tam usługi do migracji danych, zarządzania infrastrukturą, analizy danych, wizualizacji oraz uczenia maszynowego.
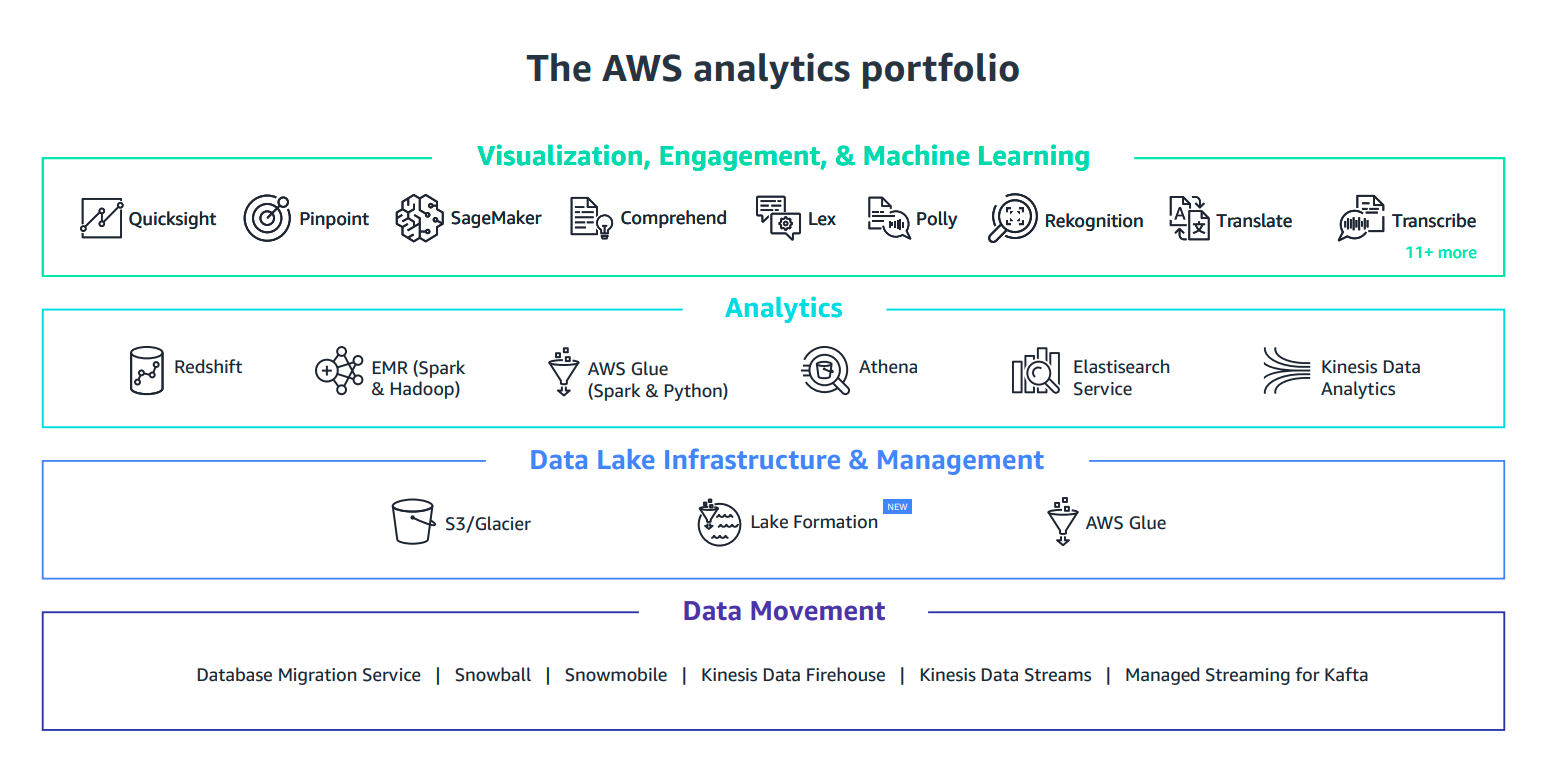
Przeanalizujmy poszczególne etapy i sprawdźmy o jakich usługach dokładnie mowa.
Konfiguracja i utrzymanie
Jeśli chodzi o konfigurację jeziora danych, mamy do tego dedykowaną, w pełni zarządzaną usługę o nazwie AWS Lake Formation. Pozwala ona na pełną automatyzację, jeśli chodzi o budowę bezpiecznego jeziora danych — i możemy to też zrobić za pomocą kilku kliknięć. Oprócz tego definiujemy miejsce, gdzie będziemy składować dane oraz jakie uprawnienia należy zaaplikować. Następnie AWS zbiera, kataloguje i organizuje dane w ramach usługi Amazon S3, która jest fundamentem, jeśli chodzi o składowanie danych, następnie konfiguruje gotowe definicje przepływów do czyszczenia i klasyfikacji danych za pomocą usługi AWS Glue.
Interaktywna analiza danych
Jeśli mowa o analityce, najważniejszą usługą w tej gałęzi jest Amazon Athena — czyli w pełni zarządzany silnik zapytań, który przeszukuje dane składowane w Amazon S3 oraz Amazon Glacier z wykorzystaniem standardowej składni SQL. Nie potrzebujemy tworzyć ani zarządzać dodatkową infrastrukturą — wystarczy skonstruować zapytanie i w kilkanaście sekund otrzymamy rezultaty, płacąc tylko i wyłącznie za rozmiar przeszukiwanego zbioru (to jasny motywator do utrzymywania porządku i unikania tzw. bagna z danymi — ang. data swamp).
Przetwarzanie danych
Myślę, że nie ma tutaj potrzeby przedstawiać jednego z najbardziej znanych serwisów dostępnych na platformie AWS — Amazon EMR. Służy on do przetwarzania dużych zbiorów danych za pomocą Apache Spark i Apache Hadoop — a to wszystko w łatwy, szybki i w opłacalny sposób. Ta w pełni zarządzana usługa wspiera 19 różnych rozwiązań opartych o projekty open source, wliczając w to np. zarządzane notatniki Jupyter do interaktywnej analizy danych, eksploracji i współpracy w zespołach.
Hurtownie danych
W tej gałęzi również mamy do dyspozycji w pełni zarządzany serwis — Amazon Redshift. Pozwala on na uruchamianie złożonych, analitycznych zapytań na ustrukturyzowanych petabajtowych zbiorach danych — a wszystko za mniej niż 1/10 kosztu rozwiązań tradycyjnych. Jedną z dodatkowych usług w tym zakresie jest Redshift Spectrum, który pozwala na uruchamianie zapytań SQL bezpośrednio na eksabajtach danych (ustrukturyzowanych lub nie) składowanych w Amazon S3, bez potrzeby ich przemieszczania czy kopiowania.
Analiza danych w czasie rzeczywistym
W tej sekcji warto zwrócić uwagę na grupę usług w ramach Amazon Kinesis. Te rozwiązania służą do zbierania, przetwarzania, analizy i wysyłania danych strumieniowych do jeziora danych — mowa tu o danych telemetrycznych, logach aplikacyjnych, oraz akcjach użytkowników. Dzięki takiemu podejściu możemy reagować i wyciągać wnioski płynące z danych w czasie rzeczywistym, bez oczekiwania na określony moment lub pełen zbiór danych.
Analityka operacyjna
Nie wolno nam zapominać o tym bardzo ważnym obszarze, który jest reprezentowany przez usługę o nazwie Amazon Elasticsearch Service. Pozwala ona na przeszukiwanie pełnotekstowe, eksplorację, filtrowanie, agregację i wizualizację danych w czasie rzeczywistym. Dzięki temu możemy pozwolić sobie na szybki i efektywny monitoring, analizę logów aplikacyjnych, akcji użytkowników oraz wielu innych metryk biznesowych.
Wizualizacja danych
Dzięki usłudze Amazon QuickSight, możemy zbudować imponujące wizualizacje oraz bogate panele, które będą dostępne z poziomu przeglądarki lub urządzeń mobilnych, bez potrzeby wykorzystania zewnętrznych usług.
Rekomendacje, Prognozowanie i Predykcja
W tej sekcji należy wspomnieć o zestawie dedykowanych usług. Pierwszą z nich jest Amazon Personalize, która skupia się na zwiększaniu zaangażowania użytkowników za pomocą uczenia maszynowego, w postaci silników rekomendacji, dostosowanych wyników wyszukiwania oraz celowania akcji marketingowych. To wszystko bez potrzeby własnoręcznego budowania modeli ani eksperckiej wiedzy na ten temat — wystarczy, że będziemy zbierać dane z naszych aplikacji, a rozwiązanie będzie w stanie rozpoznać, co niesie ze sobą wartość, a co jest szumem informacyjnym, jaki algorytm zastosować, i jak wytrenować oraz zoptymalizować wykorzystywany silnik.
Kolejną usługą jest Amazon Forecast, który jest usługą w pełni zarządzaną, tak jak poprzedni serwis, i dostarcza możliwość prognozowania oraz analizy trendów bez potrzeby i znajomości uczenia maszynowego. Warto nadmienić, że w obu przypadkach wykorzystujemy wiedzę i doświadczenie, z których korzysta globalny gigant — Amazon.com.
Na sam koniec trzeba wspomnieć o usłudze Amazon SageMaker. To w pełni zarządzany kombajn do uczenia maszynowego, który pozwala na eksplorację, budowanie, trenowanie i wdrażanie naszych modeli. Dostarcza on wszystko, co potrzebne do pracy z ML, wliczając takie elementy jak zarządzanie zbiorami treningowymi, automatyczny wybór algorytmu i jego optymalizacja (ang. hyperparameter tuning), szeroki wybór bibliotek, oraz możliwość wdrożenia modelu wraz z automatycznym skalowaniem maszyn wykorzystywanych do wnioskowania lub predykcji.
Podsumowanie
Zaprzęgnięcie danych do pracy jest jednym z największych wyzwań rosnącego biznesu. Dane powinny być naszym kapitałem, a nie zobowiązaniem. Architektura jeziora danych daje olbrzymią przewagę konkurencyjną, jest motywatorem innowacji, oraz może dostarczać bezcenne informacje, które są ukryte w oceanie danych.
Bynajmniej, ogarnięcie tego oceanu nie jest prostym wyzwaniem, w szczególności, jeśli chodzi o infrastrukturę. Dlatego każda pomoc, która jest dostarczona ze strony dostawcy chmury, jest tutaj na wagę złota. Pozwoli to Twojej firmie skupić się na tym, co wartościowe dla Twojego biznesu. Zamiast zwiększać koszty operacyjne i budować zbędną złożoność możemy skorzystać z rozwiązań w pełni zarządzanych.
W takim przypadku warto zaufać dostawcy i skupić swoje wysiłki na innowacji oraz budowaniu biznesu. AWS za pomocą swojego bogatego portfolio usług pomaga odpowiedzieć na potrzeby, które pojawiają się na każdym etapie związanym z budowaniem jeziora danych. Teraz trzeba tylko z tego skorzystać.
Ten artykuł ukazał się oryginalnie w języku angielskim jako Why do you need a Data Lake, and how AWS can help you with that?