Wyobraź sobie jezioro składające się z nieskończonej ilości kropel połączonych ze sobą tylko dlatego, że znajdują się w tym samym miejscu. Każda kropla to jakiś zbiór danych, wszystkie razem stanowią pewną całość (np. dane przedsiębiorstwa, dane dot. badań nad nowym lekiem itp.). Teraz, gdy widzisz ten obraz w swojej głowie to dobry moment, aby przedstawić Ci definicję.
Definicja
Data lake to (centralne) repozytorium, które przechowuje ustrukturyzowane i nieustrukturyzowane dane w dowolnej skali. W jeziorze danych przechowujesz dane w takim formacie w jakim oryginalnie są (bez konieczności ich uprzedniej transformacji i strukturyzacji) lub przetworzone jeśli Ci to bardziej odpowiada (np. do formatu Apache Parquet).
Bezpośrednio na tych danych uruchamiasz różne rodzaje analiz, które możesz wykorzystać do wizualizacji (generowanie raportów, dashboardy itp.), przetwarzania big-data, analityki w czasie rzeczywistym oraz machine learning.
Wszystko po to, aby podejmować (automatycznie) lepsze decyzje.
Skąd ta nazwa?
Jeziora danych swą nieco dziwną nazwę zawdzięczają idei, która stawia je w opozycji wobec hurtowni danych, w których dane muszą być zgodne z góry przyjętą, narzuconą strukturą. Jak woda w butelce na linii produkcyjnej.
Dane, podobnie jak woda w jeziorze znajdują się w swojej naturalnej formie i nie są podawane takim procesom standaryzacji… stąd data lake. 🙂
Ukucie terminu data lake przypisuje się Jamesowi Dixon (ówczesnemu) CTO firmy Pentaho. Powiedział on
The difference between a data lake and a data warehouse is that in a data warehouse, the data is pre-categorized at the point of entry, which can dictate how it’s going to be analyzed. This is especially true in online analytical processing, which stores the data in an optimal form to support specific types of analysis.
Do czego służy data lake?
Mimo tego, iż koncepcja data lake liczy sobie blisko dekadę (a big data jeszcze więcej) dopiero od niedawna staje się powszechna, moim zdaniem, głównie na skutek popularyzacji chmury publicznej. To przecież usługi zarządzane wyższego rzędu zdejmują z nas ciężar samodzielnej instalacji oraz konfiguracji specjalistycznego oprogramowania oferując praktycznie bezobsługowe rozwiązania. A to drastycznie obniża próg wejścia w świat data lake.
Pytanie: Po co mielibyśmy do niego wchodzić?
Z definicji data lake daje nam dużo większą elastyczność techniczną i biznesową. Składowanie danych w źródłowym formacie pozwala je analizować z wielu perspektyw, również tych, które pojawiły się post factum, co często nie jest możliwe w przypadku baz danych oraz hurtowni danych, gdzie dane są przechowywane z myślą o konkretnych (znanych zawczasu) zastosowaniach i przystosowane do odpowiadających im analiz.
Do najpopularniejszych obecnie zastosowań możemy zaliczyć:
- Analiza danych organizacji pochodzących z wielu wewnętrznych systemów
- IoT - analiza i przetwarzanie danych pochodzących z wszelkiego typu urządzeń
- Analiza logów - biznesowych (np. klikanie w reklamy) jak i technicznych (np. AWS CloudTrail Logs)
- Uczenie maszynowe (machine learning) w celu odnajdywania heurystyk i przewidywania zdarzeń (np. awaria maszyny lub zachowanie klienta)
- Badania naukowe - choćby w medycynie (ludzki genom, leki itd.), naukach społecznych, ekonomii i wielu innych.
Jak to działa?
Jeziora danych przechowują ogromne ilości danych, co jest naturalną konsekwencją tego, że po pierwsze produkujemy coraz więcej danych 😉, a po drugie dlatego, że można w nich trzymać dane w dowolnym formacie. To, że nie musimy ich poddawać Transformacji w takim znaczeniu jakie mamy w procesach ETL, znanych choćby z hurtowni danych, znakomicie upraszcza procesy zasilania. (W praktyce nie mamy tutaj procesów ETL, a ELT ale o tym w kolejnym artykule).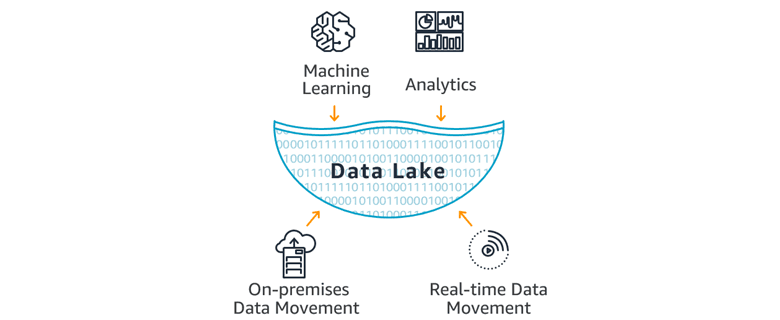
Dzięki czemu mamy tylko jedno (centralne) miejsce do przechowywania danych, w którym możemy umieszczać dane ze wszystkich źródeł (aplikacji, systemów) jakimi dysponujemy.
W przypadku AWS tym miejscem jest oczywiście Bucket w S3, dzięki czemu dane są bezpieczne (w kontekście niepowołanego dostępu do nich jak i ich utraty z powodu awarii). AWS zapewnia też niezbędną do takich zostawań skalowalność, dzięki czemu nasz data lake możemy zapełniać danymi w dowolnym tempie bez obawy o to, że zostanie zarżnięty wydajnościowo.
Dzięki temu, że dane trzymamy na S3 to w naturalny sposób uzyskujemy rozdział pomiędzy warstwą przechowującą dane, a warstwą, która je analizuje. Jak się domyślasz, ta druga jest bardzo zasobożerna jeśli chodzi o moc obliczeniową (compute). Taki podział umożliwia nam niezależne skalowanie warstw, a tym samym lepszą wydajność i niższe koszty rozwiązania.
A co Data Lake ma wspólnego z serverless?
W chmurze AWS usługi z których można zbudować jeziora danych są w pełni zarządzane i działają w modelu serverless. Nie musisz powoływać serwerów ani płacić za ich bezczynność wtedy, gdy nie korzystasz aktywnie z takiego repozytorium. Oczywistym wyjątkiem jest oczywiście AWS S3, w którym płacimy za przechowywane dane, natomiast transformacje (np. AWS Glue) i analityka (Amazon Athena) są rozliczane podobnie jak AWS Lambda w modelu pay-as-you-go.
Podsumowanie
Zarządzane usługi pozwalają wykorzystać maksymalnie dużo czasu architektów i inżynierów tam gdzie to ważne, czyli na dojściu do oczekiwanych wyników analizy i dalszym ich wykorzystaniu w całym rozwiązaniu, które budujemy. Dzieje sie tak, gdyż nie jesteśmy zmuszeni do samodzielnego powoływania serwerów i instalacji na nich specjalistycznego oprogramowania (o którym często nie mamy żadnego pojęcia od strony administracyjnej). Nie musimy się też troszczyć o bezpieczeństwo tych serwerów, ponieważ jest to teraz odpowiedzialność specjalistów po stronie AWS.
Rozwiązania klasy data lake, dają nam możliwość pracy na danych, na których w żaden inny sposób byśmy nie mogli działać bez uprzedniego poniesienia kosztów ich analizy, specyfikacji i przetworzenia. Taka inwestycja w obrobienie danych rzadko kiedy ma miejsce (po wdrożeniu, gdyż często jest projektem samym w sobie).
W przeciwieństwa do hurtowni danych, brak schematów i narzuconych struktur pozwala wielokrotnie wykorzystać te same zbiory w rożnych analizach oferując biznesową elastyczność i technologiczną prostotę, równocześnie przy niskich nakładach poniesionych na zasilanie jeziora danymi.