Czyli czym różni się serverless od klasycznych rozwiązań?

Co to jest serverless?
Pomimo tego, iż z serverless jestem związany od 2016 roku to wbrew pozorom, jest to bardzo trudne pytanie. Aktualnie nie ma jednej definicji tego terminu. Ba! Nie ma nawet zgody co do przypisania serverless do jakiejś szerszej kategorii (przypomina się dziobak z biologii, który został w końcu ssakiem :-). Jeśli chodzi o serverless to jedni twierdzą, że to architektura, inni, że technologia, podejście do wytwarzania oprogramowania, a nawet „spektrum”.
To wszystko i jeszcze więcej ujął w swoim wyczerpującym, ponad 10-cio stronicowym, artykule Jeremy Daly. Pomimo bycia niekwestionowanym autorytetem w temacie, nawet jemu nie udało się dokładnie zdefiniować tego terminu. Wytrwałym polecam lekturę tutaj.
Brak jednoznacznej definicji nie służy nikomu, ale trzeba jakoś żyć. Trudno jest o czymś mówić, jeśli się tego nie nazwie. Uważam, że nie ma sensu bić piany i toczyć leksykalne potyczki. Aby zrozumieć idee serverless potrzebna nam wystarczająco dobra definicja. Zatem moim zdaniem:
Definicja serverless
Jest to architektura, a zarazem podejście do wytwarzania oprogramowania polegające na łączeniu ze sobą różnych usług (bloki budowlane) dostępnych w chmurze publicznej w taki sposób, że:
- Nie musimy zarządzać infrastrukturą (począwszy od topologii sieci, aż do serwera aplikacji włącznie),
- Końcowe rozwiązanie jest wysokoskalowalne,
- Końcowe rozwiązanie jest wysokodostępne,
- Płacimy tylko za realnie wykorzystane zasoby (usługi), pomimo tego, iż są one non-stop gotowe do użycia przez nasze rozwiązanie.
Jak rozumieć tą definicję?
Po pierwsze serverless to nie jest żadna specyficzna technologia. Amazon, Google, Microsoft i jeszcze wielu innych dostawców mają własne wachlarze usług serverless w swojej ofercie. Ich usługi to moim zdaniem bloki budowlane, z których, można składać własne rozwiązania. W TOGAF (framework architektury korporacyjnej) blok budowlany reprezentuje nadający się do ponownego użycia, komponent IT lub architektoniczny, który może być połączony z innym blokiem budowlanym w celu dostarczenia rozwiązania. Łącząc bloki budowlane (usługi) ze sobą tworzymy architekturę - dla mnie, serverless ma wszystkie niezbędne znamiona, aby sklasyfikować go jako architekturę. Natomiast, podejście do wytwarzania oprogramowania najlepiej oddaje ideę, jaką reprezentuje – do czego powrócę później.
Łączenie bloków budowlanych, usług, czy komponentów (jak zwał tak zwał) nie jest niczym nowym w IT. Robimy to od dziesiątek lat. Natomiast, po raz pierwszy możemy się skupić na możliwościach oferowanych przez te komponenty bez zarządzania infrastrukturą, na której są realizowane.
Super szybki kurs na architekta chmury
Aby podkreślić różnicę pomiędzy klasycznymi architekturami a serverless zrobię teraz super szybki kurs projektowania wysokodostępnych i skalowalnych systemów na chmurze AWS. Tego uczą i wymagają na egzaminie na certyfikowanego architekta AWS. Dla jasności, przy rozwiązaniach on-premises / fizycznych przemnóż poziom komplikacji i obciążenia pracą przez 100 :-)
Aby nie zostać posądzonym o manipulację, posłużę się referencyjną architekturą od AWS dla klasycznej, trójwarstwowej aplikacji webowej beż żadnych dodatków i udziwnień (cache, read-replica itp.). Jak popatrzysz na rysunek, to zobaczysz czemu zawdzięcza swą nazwę: bazy danych, serwery aplikacji oraz serwery webowe są rozmieszczone oddzielnie, tworząc trzy warstwy.
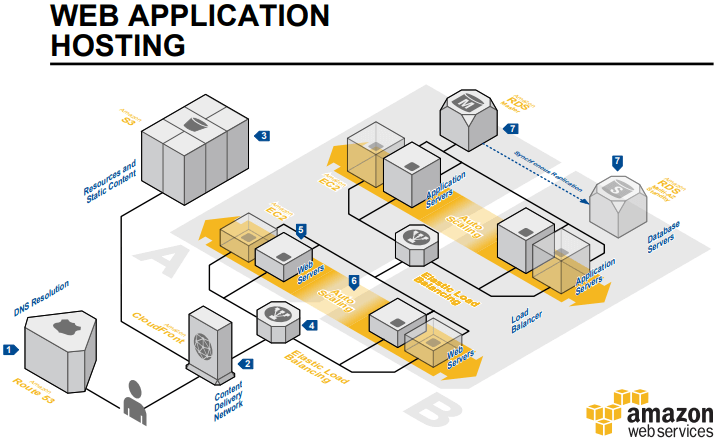
Szybki kurs architektury na AWS - przystępujemy to projektowania
- Definiujemy wirtualną sieć prywatną VPC.
- Dzielimy naszą sieć prywatną na podsieci.
a. Mamy 3 warstwy, więc będziemy potrzebowali 3 podsieci (subnet).
b. Eee źle! Aplikacja ma być wysoko dostępna, wiec musi działać w dwóch strefach dostępności (Availability Zone - fizycznie osobne datacenter AWSa, minimum 3 na jeden region geograficzny)
c. Czyli potrzebujemy 6 podsieci po 3 na każdą strefę dostępności
d. Eee źle! A gdzie skalowalność? No tak, ponieważ będziemy mieli więcej niż po jednym serwerze w danej warstwie, to jakoś musimy dystrybuować ruch do wielu maszyn. Potrzebny nam Load Balancer, który uwaga potrzebuje własnych podsieci.
e. Dobra, czyli 4 podsieci razy 2 strefy dostępności daje 8 podsieci w sumie.
f. Super. Teraz adresacja podsieci, przecież każda posiec musi mieć swój przedział adresów IP, aby mogła funkcjonować.
g. Teraz definiujemy wiele routing table dla tych podsieci, aby ruch sieciowy działał.
h. Nie wchodząc w szczegóły, będziemy potrzebowali jeszcze NAT Gateway i Internet Gateway, aby serwery, które utworzymy, miały dostęp do sieci.
i. Poprawiamy routing tables.
j. Załóżmy, że topologia sieci jest już OK. - Teraz zajmijmy się serwerami.
a. Bazy danych – korzystamy oczywiście z RDS, załóżmy, że uruchomimy MySQL w modelu Master – Slave, to znaczy, że gdy Master padnie to AWS przełączy nas na Slave i w mniej niż sekundę nasza aplikacja będzie znów działać. Super, co nie?
b. Serwery aplikacji. Minimum dwa, po jednym na każde Availability Zone weźmy sobie Amazon Linuxa, zainstalujmy tam Jave, odpalmy naszą aplikację napisaną w Spring Boot. Lub cokolwiek innego co udostępnia jakieś tam API dla ostatniej warstwy webowej.
c. Serwery webowe, znow dwa, znów linux, tutaj będziemy mieli jakiś serwer http. Nginx, tomcat. Co kto lubi? :-)
d. Super. Koniec. Ufff…
e. Eee źle. Miało być skalowalne przecież. Trzeba serwery aplikacji i webowe wsadzić w Auto Scalling Group’y – dwie, po jednej na warstwę.
f. Skalowanie bazy pomijam!
g. Wszystko?
h. Gdzie tam, trzeba zadbać o bezpieczeństwo.. Tworzymy Secuirty Groups dla każdej warstwy osobno.
i. Definiujemy role, dostępy. - I tak dalej…
- A potem jeszcze dalej…
Dobra zaczynam siebie nienawidzić, że kazałem Ci to czytać :-P
A to tylko robota przy projektowaniu i tworzeniu infry. Tak, zgadzam się, że tę robotę wykonuje się w praktyce raz pisząc kod (Infrastructure as Code), ale wciąż trzeba przejść przez te wszystkie etapy. Budując każdy nowy projekt od nowa. Potem trzeba jeszcze doglądać tych serwerów, monitorować, paczować (przyjaźnie macham ręką w kierunku Intela, dziękując za dziury bezpieczeństwa w ich procesorach) i tak dalej…
Jednym zdaniem: W ciul roboty.
Dobra wiadomość: W serverless w większości została ona przejęta przez dostawcę chmury.
Specjalnie wymieniłem tak długą (ale niepełną, bo już sam siebie zanudziłem) listę kroków, ponieważ zazwyczaj w artykułach na temat serverless pada tego typu wypowiedź:
„Brak administracji serwerami i konieczności projektowania infrastruktury sieciowej oznacza oszczędność czasu, zwiększenie bezpieczeństwa i ograniczenie kosztów operacyjnych. „
To jest oczywiście PRAWDA! Jednak bardzo często ludzie w IT nie mają świadomości, jak straszna jest alternatywa. Z mojego korpo-doświadczenia wynika, że większość developerów nie potrafi uruchomić produkcyjnie aplikacji, którą programują!
Wyobraź sobie, że Twój mechanik samochodowy jest mega specem od silników i zawieszenia, ale nie potrafi prowadzić samochodu. Dziwne, co nie? W IT nie!
W czasach przed DevOps to nie było problem, podział był wręcz wymuszany organizacyjnie (a czasem nawet prawnie). Ale teraz czasy się zmieniły i od developerów oczekuje się większej świadomości na temat utrzymania aplikacji, którą tworzą. W końcu DevOps to rozwiązywanie problemów operacyjnych metodami programistycznymi. Nawet jeśli w Twojej firmie nadal macie adminów, sieciowców i innych speców od utrzymania (całe to Ops) to wiedz, że ta praca istnieje i ktoś ją w klasycznych architekturach wykonuje (chcąc nie chcąc), nawet jeśli przed Tobą, jako developerem, jest to ukryte.
Wróćmy do definicji serverless. Już wiesz jak rozumieć brak zarządzania infrastrukturą. Przejdźmy zatem dalej.
Wysokoskalowalne i wysokodostępne
Wysokoskalowalne i wysokodostępne rozwiązania otrzymujemy w serverless korzystając z usług (nasze bloki budowlane) w chmurze, które mają te charakterystyki wbudowane.
Posłużę się przykładem, aby wyjaśnić tę kwestię.
Powyżej w architekturze trójwarstwowej aplikacji webowej stworzyliśmy dwie instancje bazy danych MySQL: Master i Slave. Odczyt i zapis był wykonywany na masterze, wszelkie zmiany (update, delete) są synchronizowane synchronicznie do slave. W razie awarii mastera AWS automatycznie przekierowuje połączenia (przez zmianę w DNS) na maszynę slave. Takie rozwiązanie zapewnia tylko wysoką dostępność aplikacji. W żaden sposób nie wspiera skalowalności.
W świecie serverless wykorzystamy innego rodzaju bazę danych o nazwie AWS DynamoDB. Charakteryzuje się ona:
- Wbudowaną wysoką dostępnością i trwałością danych – są one automatycznie replikowane do różnych Availability Zones w regionie. Nigdy nie są przechowywane na pojedynczej maszynie!
- Wbudowaną wysoką skalowalnością – może obsłużyć chwilowe obciążenia (peak) rzędu 20 milionów requestów na sekundę. Wyobraź to sobie, ponad połowa Polaków klika w tym samym momencie i generuje taki ruch :-) Ta baza jest niewiarygodnie skalowalna, ale też bardzo droga, jeśli zaprzęgniemy ją do super dużych obciążeń lub będziemy w niej trzymać dużo danych.
- Tym, że jest w pełni zarządzana przez AWS – oznacza to, że nie musimy uruchamiać żadnych serwerów, na których jest ona instalowana. Przypominam, w RDS musimy uruchomić wirtualne maszyny EC2, na których AWS zainstaluje nam MySQL (upraszczam tutaj celowo). OS na takich maszynach trzeba aktualizować, paczować itd. Tutaj tego nie ma.
Na marginesie: DynamoDB jest również świetnym przykładem bloku budowlanego, który łatwo się integruje z innymi. Usługa potrafi automatycznie generować zdarzenia (DynamoDB Streams API) i przesyłać do innych powiązanych usług. Pozwala to w trywialny sposób projektować systemy zgodnie z Event Driven Architecture. Przykładowo, za każdym razem, gdy ktoś doda nowe zamówienie do bazy, ta informacja zostanie rozesłana do powiązanych usług. Automatycznie, bez budowania żadnych messagebus’ów czy innych systemów komunikacji. Jest to nowoczesne podejście, które staje się coraz bardziej popularne w ostatnich latach.
Koszty w serverless
Ostatnią cechą charakterystyczną serverless, według definicji, jest jej model kosztowy. Aby uznać rozwiązanie lub usługę za serverless, musi ona być rozliczana w modelu pay-as-you-go. Czyli opłaty są pobierane za realne użycie, a nie czas trwania usługi.
Posłużmy się przykładem. Załóżmy, że mamy własną aplikację typu SaaS, którą sprzedajemy innym biznesom w modelu subskrypcji. Dajmy na to, że to aplikacja kadrowa, pozwala pracownikom naszych klientów składać wnioski urlopowe przez Internet.
W klasycznej architekturze webowej aplikacji trójwarstwowej (omówionej powyżej) mieliśmy uruchomione w usłudze RDS dwa serwery EC2, na których działały dwie instancje bazy MySQL: master i slave. Bez różnicy czy ktoś czytał, zapisywał czy kompletnie nic nie robił z tymi bazami, to musimy za nie płacić. Podwójnie bo są dwie. Model opłaty usługi EC2 zależy od czasu. Bez różnicy czy wykorzystujemy ten zasób w jednym czy w stu procentach. Płacimy tyle samo. Owszem, EC2 jest rozliczany, co do sekundy, ale ponieważ bazy danych zazwyczaj są włączone non stop to wiele nam to nie pomaga. W perspektywie naszej aplikacji SaaS możemy założyć, że prawie nikt nie będzie z niej korzystał od godziny 18:00 do 7:00 rano następnego dnia. My, jako biznes, płacimy za niewykorzystane zasoby, które generują nam 13 godzin dziennie starty!
To daje nam 13/24 = 54% niepotrzebnych kosztów!W świecie serverless wykorzystalibyśmy DynamoDB. Tutaj płacimy za ilość danych przechowywany oraz ilość i wielkość odczytów i zapisów do bazy, ale nie za czas życia bazy. Od 18-stej do 7-mej rano, jeśli nikt nie korzystał z naszej aplikacji nie ponosimy kosztów odczytu/zapisu tylko ewentualnie koszt przechowywania danych. Warto tu jednak zaznaczyć, że powstało kilka wzorców projektowych, które pozwalają na wykorzystanie mocy bazy przy zniwelowaniu kosztów przechowywania w niej danych.
Ponieważ nie było zapisów, nie było też kosztów. Nasza strata wynosi okrągłe 0%.
Podsumowując,model kosztowy serverless przypomina model opłat za telefon komórkowy bez abonamentu, w którym płacimy tylko za wykonane rozmowy. Pomimo tego, że telefon jest ciągle podłączony do sieci operatora i gotowy do użycia (może odebrać nadchodzące połączenie lub wykonać wychodzące) my za to nie płacimy, ten koszt operacyjny bierze na siebie operator.
W skrócie opłata za serverless przypomina rachunek za telefon, a opłata za klasyczne rozwiązania przypomina bardziej rachunek za gaz, w którym mamy:
• opłatę taryfową
• abonament
• opłatę sieciową stałą
• opłatę sieciową zmienną
• zużycie
WTF?! Ja nie rozumiem tych rachunków za gaz…
Mam nadzieję, że teraz różnice w modelach kosztowych są dla Ciebie jasne. Zapewne teraz już rozumiesz, dlaczego serverless jest tak popularny wśród startupów, które mają ograniczone fundusze, a czasem ich brak (wiem to z własnego doświadczenia) i nie chcą ich trwonić na niepotrzebnie działające serwery.
Total Cost of Ownership i Activity Based Costing
Nie był bym sobą gdybym nie wspomniał w kontekście kosztów o jeszcze jednej rzeczy. Serverless jest również bardzo chętnie wykorzystywany przez wielkie korporacje (np. Coca-Cola), które nie muszą, a jednak liczą dokładnie koszty. Zagadnienie liczenia kosztów w IT jest bardzo trudne. Kto się kiedyś interesował Total Cost of Ownership lub Activity Based Costing ten wie, że niesamowicie trudno jest dokładnie powiedzieć: Ten system kosztuje nas 38 674 złote miesięcznie.
W całkowity koszt utrzymania wchodzi mnóstwo elementów, takich jak kadry, sprzęt, internet, obsługa, itp. aż do rachunku za prąd i budynek serwerowni. Jak to wszystko adekwatnie podzielić pomiędzy N systemów IT, które masz u siebie w firmie? To jest aspekt księgowy, natomiast aspekt biznesowy jest taki, że mega trudno jest odpowiedzieć na pytanie: Ile kosztuje nas jedna „transakcja” klienta (np. złożenie wniosku o urlop)? To jest 8 groszy, czy może złoty dwadzieścia? Tego typu wiedza pozwala skorelować koszty z ceną usługi dla klienta i realnie określić naszą marżę na tej konkretnej usłudze. Wiem, że to zagadnienia biznesowe, które nie interesują przeciętnego developera, ale przecież Ty nie jesteś przeciętny! :-D
Tak na marginesie, uważam, że model pay-as-you-go będzie się robił coraz bardziej popularny. Wynika to z ewolucji technologi. Jest to bardzo fascynująca wycieczka po historii IT, którą może kiedyś Wam opowiem :-)
Podsumowanie
Dziękuję za przeczytanie tak długiego tekstu. W nagrodę za wytrwałość zdjęcie dziobaka dla Ciebie!

Mam nadzieję, że po tym artykule masz już całkiem dobre pojęcie o tym, czym jest serverless. Wiesz, czym się różni od klasycznych systemów i jaki jest jego model kosztowy służący do rozliczeń.
Jedyne, czego nie wytłumaczyłem, to dlaczego uważam serverless za podejście do wytwarzania oprogramowania. „Podejście” w rozumieniu takim, jak rozumiemy Agile czy DevOps, ale o tym napiszę w kolejnym artykule.
Udanej reszty dnia!