Jedną z korzyści, o której usłyszysz, gdy ludzie będą Cię przekonywać do architektury serverless, jest to, że “sama się skaluje i nigdy nie musisz się o to martwić”.
Chciałbym, żeby to była prawda.
Ale tak nie jest.
Prawdą jest, że dostawca chmury obsługuje zdarzenia skalowania za Ciebie. I do tego całkiem nieźle. Dzieje się to automatycznie bez żadnej ingerencji z Twojej strony i skaluje się praktycznie do każdego poziomu (zakładając, że zmieniłeś limity usług AWS).
To, co nie jest prawdą, to fakt, że nie musisz się o to martwić. Koniecznie musisz wziąć pod uwagę skalę podczas projektowania aplikacji serverless.
Projektując aplikację, musisz znać z grubsza stopień, w jakim będą napływać żądania.
Czy to 1 żądanie na sekundę? 10? 1,000? 100,000?
Dla każdego rzędu wielkości, musisz rozważyć, jak poradzisz sobie ze zwiększonym obciążeniem w całym systemie. Skalowanie nie odnosi się tylko do sposobu w jaki API Gateway obsługuje ruch. To również zachowanie bazy danych, procesów backendowych i własnych API, które razem obsługują ruch. Jeśli co najmniej jeden z tych elementów nie zostanie przeskalowany do odpowiedniego poziomu, napotkasz wąskie gardło i zmniejszoną wydajność aplikacji.
Dzisiaj porozmawiamy o różnych sposobach budowania aplikacji w oparciu o przewidywaną skalę (plus bonusowo również bezpieczeństwa).
Nota: Nie ma standardowych nazw ani definicji branżowych dla różnych poziomów skali. Nazwy, których będę używać, są wymyślone i nie mają na celu odzwierciedlenia jakości lub znaczenia oprogramowania.
Mała skala (1-999 żądań na sekundę)
Obsługując system na małą skalę, masz szczęście. Możesz budować bez zbyt wielu rozterek architektonicznych. Teoretycznie wszystko powinno po prostu działać. Nie oznacza to jednak, że bierzesz pierwszy z brzegu przykładowy projekt i deployujesz go na produkcję (nigdy nie powinieneś używać POC na produkcji).
Oznacza to jednak, że w większości sytuacji można zaprojektować aplikację zgodnie ze standardowymi wzorcami dla architektur serverless.
Przy małej skali podstawowe bloki budowlane serverless są Twoimi najlepszymi przyjaciółmi i zaprowadzą Cię daleko. Ale bez względu na to, jaki poziom skali planujesz, musisz pamiętać o sprawdzeniu limitów dla usług, z których będziesz korzystać. Rozważmy następujący wzorzec dla interfejsu API na małą skalę.
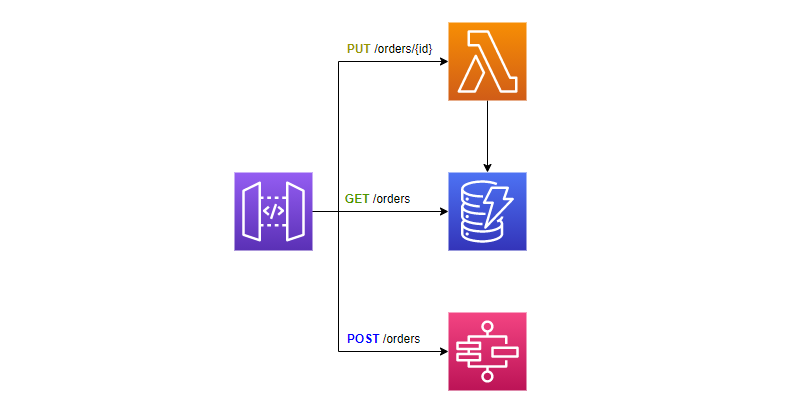
Dla takiej architektury, limity usług, które będą Cie interesowały to:
- Maksymalna współbieżność funkcji Lambda (
concurrent executions) - domyślnie: 1000 - Rozmiar
Capacity unitw DynamoDB - Maksymalna ilość uruchomień maszyny stanów (
start execution) w usłudze Step Functions - domyślnie: 1300 na sekundę w niektórych regionach, 800 w innych
Istnieją inne limity dla usług, które ta architektura zużywa, ale przy tej skali nie natrafimy na nie.
Jeśli osiągniemy szczyt naszej skali i / lub nasz średni czas wykonania funkcji Lambda jest dłuższy niż sekunda, dobrym rozwiązaniem może okazać się zażądanie zwiększenia limitu concurrent executions usługi Lambda. Jeśli twój średni czas wykonania jest bardzo niski, rzędu 200ms i mniej, oznacza to, że wszystko jest w porządku.
Jeśli zaczniesz regularnie osiągać 70-80% limitu usługi, powinieneś poprosić o zwiększenie.
W przypadku DynamoDB masz kilka opcji. Można użyć mechanizmu provisioned throughput, który ustawia konkretną liczbę odczytów i zapisów na sekundę dla tej bazy lub można użyć trybu on-demand, który skaluje się sam, jeśli masz zmienne lub nieznane obciążenia.
Jeśli korzystasz z trybu on-demand, nie musisz się martwić o skalowanie. DynamoDB będzie skalować się automatycznie. Ale jeśli używasz provisioned throughput, musisz upewnić się, że ustawiłeś przepustowość, której naprawdę potrzebujesz.
W przypadku Step Functions musisz zachować ostrożność co do liczby uruchamianych standardowych maszyn stanów. Domyślna liczba w takim przypadku wynosi 1 300 na sekundę z dodatkowymi 500 (tryb burst) w us-east-1, us-west-1 i eu-west-1. Jeśli Twoja aplikacja działa poza tymi regionami, domyślnie jest ograniczona do 800 uruchomień na sekundę.
Należy zauważyć, że ten limit dotyczy tylko uruchamiania nowych wykonań maszyny stanów w okresie jednej sekundy. Możesz mieć do 1 miliona działających jednocześnie wywołań, zanim Twoje nowe żądania zaczną być przycinane (throttling). Ale w tej skali prawdopodobnie nie musimy się o to martwić.
Średnia skala (1 000-9 999 żądań na sekundę)
Następny poziom skali zdecydowanie wymaga pewnych rozważań projektowych. Jeśli spodziewasz się stałego obciążenia rzędu 1k - 10k żądań na sekundę, musisz zaplanować odpowiednią odporność na błędy (fault tolerance). W tej skali, jeśli 99,9% Twoich żądań zakończy się powodzeniem, oznacza to, że patrzysz na 86 400 do 864 000 niepowodzeń dziennie. Tak więc odporność na błędy i redundancja mają szczególne ważne miejsce na tym poziomie.
Chociaż zawsze powinieneś projektować tak, aby ponawiać próby, staje się to szczególnie ważne, gdy rozmawiamy o skalowaniu. Zarządzanie ponawianiem prób (retries) i odpornością na błędy w tej skali szybko staje się niemożliwym zadaniem dla ludzi, więc automatyzacja procesu jest kluczową częścią Twojego sukcesu.
Zobaczmy, jak zmienił się nasz diagram architektury po przejściu do średniej skali.
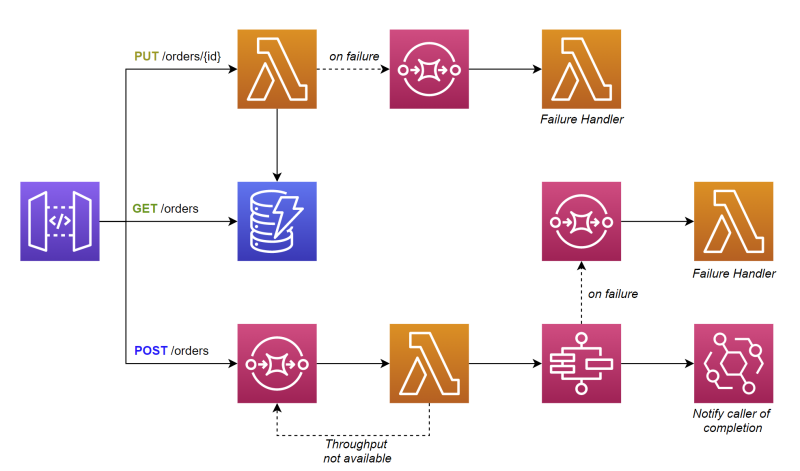
Architektura została nieco zmodyfikowana. Nadal mamy endpointy, które łączą się z usługami Lambda i DynamoDB, ale nie łączymy się już bezpośrednio z usługą Step Functions. Zamiast tego umieszczamy przed nią kolejkę SQS, aby działała jako bufor. To nieumyślnie skutkuje tym, że endpoint zamienia się w asynchroniczny.
Funkcja Lambda batchowo pobiera żądania uruchomień z kolejki, sprawdza przepustowość w Step Functions i rozpoczyna wykonywanie. Jeśli brak przepustowości, żądania wracają do kolejki, aby ponowić próbę później.
Po zakończeniu pracy maszyna stanu wysyła zdarzenie przez EventBridge, aby powiadomić wywołującego o zakończeniu operacji.
Dla takiej architektury i skali limity, na które należy zwrócić uwagę, to:
- Współbieżność funkcji Lambda (
concurrent executions) - musisz poprosić o zwiększenie, aby uwzględnić przepustowość - EventBridge
PutEvents- domyślnie 10k na sekundę, ale w niektórych regionach tak niskie jak 600 na sekundę
Zgodnie z dokumentacją, współbieżność funkcji Lambda można zwiększyć do dziesiątek tysięcy, więc jesteśmy tutaj bezpieczni i nie musimy się martwić o dodatkowy klej, który dodaliśmy między SQS i Step Functions.
Wraz ze zwiększeniem liczby funkcji Lambda w tym projekcie, musimy ustawić zarezerwowaną współbieżność (reserved concurrency) dla funkcji o niższym priorytecie. Współbieżność zarezerwowana stanowi składową całkowitej współbieżności wszystkich funkcji Lambda na koncie AWS. Ustawia się ją dla konkretnej funkcji, która będzie mogła być skalowana maksymalnie do ustawionej wartości. Zapobiega to niepotrzebnemu zużywaniu współbieżności przez funkcje o niskim priorytecie. Użycie zarezerwowanej współbieżności nadal umożliwia skalowanie funkcji do 0, gdy nie są używane.
Z drugiej strony, dostarczona współbieżność (provisioned concurrency) utrzymuje zadeklarowaną liczbę rozgrzanych funkcji Lambda, w ten sposób chroniąc nas przed cold startami. Jest to szczególnie ważne dla uzyskania jak najniższego czasu reakcji. Warto zauważyć, że funkcja Lambda może się skalować ponad tę wartość, ale wtedy mamy do czynienia z cold startem.
W tym momencie warto porozmawiać o podejściu single table design w DynamoDB i o tym, jak twój model danych jest szczególnie ważny w średniej (i dużej) skali. W single table design wszystkie typy encji danych zapisujemy w pojedynczej tabeli, a rozróżniamy je za pomocą różnych kluczy partycji. Pozwala to na szybki i łatwy dostęp do danych przy minimalnym opóźnieniu w usłudze DynamoDB.
Jednak DynamoDB ma limit 3000 jednostek odczytu read capacity units (RCU) i 1000 jednostek zapisu write capacity units (WCU) na partycję.
Jeśli Twój model danych nie dystrybuuje żądań równomiernie pomiędzy partycjami tabeli DynamoDB, to utworzysz gorącą partycję (hot partition), a Twoje żądania do bazy zaczną być przycinane (throttling). W średniej skali lub wyższej sposób zapisywania danych ma kluczowe znaczenie dla skalowalności. Pamiętaj więc, aby zaprojektować model danych w sposób, który umożliwia łatwy sharding przy zapisie, aby partycje danych były zróżnicowane.
Wiele do rozważenia, gdy osiągniemy drugi poziom skali. Ale jest jeszcze więcej do wyjaśnienia, gdy osiągniemy ostateczny poziom skali.
Duża skala (ponad 10 000 żądań na sekundę)
Justin Pirtle wygłosił na AWS re:Invent 2021 prelekcję na temat projektowania aplikacji serverless dla hiperskali. W swojej prezentacji opowiada o najlepszych praktykach dla aplikacji działających w naprawdę dużej skalę. Najważniejsze czynniki? Cache`owanie, batch`owanie, i kolejkowanie.
Mając na uwadze te czynniki, przyjrzyjmy się, jak zmienia się nasza architektura w stosunku do modelu w małej skali.
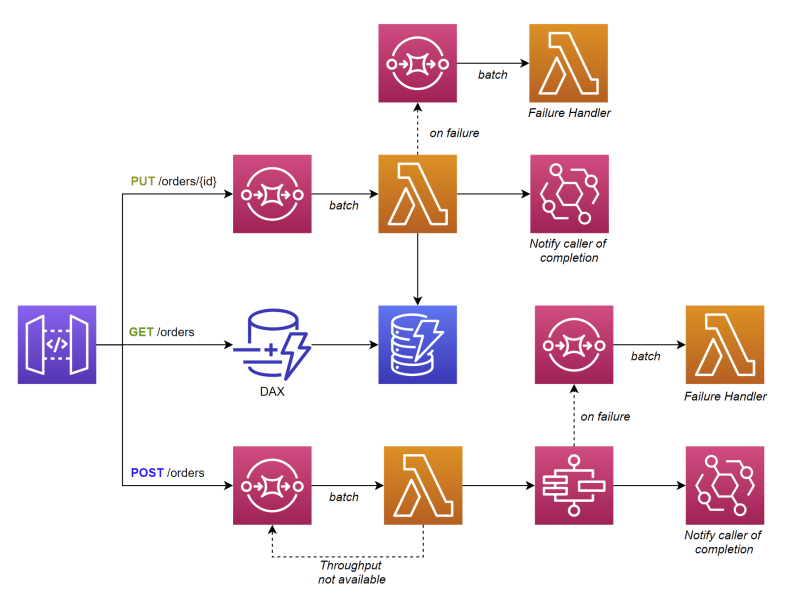
W przypadku takiej architektury w dużym stopniu polegamy na przetwarzaniu asynchronicznym. Ponieważ prawie wszystkie wywołania API powodują kolejkowanie, oznacza to, że większość wywołań będzie polegać na przetwarzaniu wsadowym w tle. API Gateway łączy się bezpośrednio z SQS, co powoduje, że funkcja Lambda pobiera partie wiadomości do przetworzenia (batching).
Po zakończeniu przetwarzania uruchamia zdarzenie, aby powiadomić o zakończeniu przetwarzania wywołującego. Alternatywnie można zastosować podejście oparte na modelu zadania, aby umożliwić osobie wywołującej wysłanie zapytania o aktualizację stanu.
Jeśli wystąpi błąd podczas przetwarzania jednego lub więcej elementów w partii (batch), można ustawić właściwość BisectBatchOnFunctionError w mapowaniu źródła zdarzeń, aby podzielić partię i ponowić próbę. Pozwala to uzyskać jak najwięcej poprawnie przetworzonych wiadomości.
Wprowadziliśmy również DynamoDB Accelerator (DAX) przed naszą tabelą, aby działał jak cache. Pomaga to utrzymać RCU na niskim poziomie, a także zapewnia mikrosekundowe opóźnienia w przypadku trafień (wartość obecna w pamięci podręcznej).
Wszystkie limity usług z poprzednich poziomów skali mają zastosowanie na tym poziomie, plus kilka dodatkowych:
- Żądania na sekundę do API Gateway
requests per second— domyślnie: 10k na sekundę dla wszystkich endpointów w regionie - Przejścia między stanami maszyny stanów w usłudze Step Functions
state transitions— 5k na sekundę w niektórych regionach, w innych 800 na sekundę
Przy dużej skali, architektoniczne rozważania wchodzą na wyższy poziom. Ponieważ istnieje tak wiele limitów usług, które należy kontrolować i zwiększać, dobrym pomysłem jest rozdzielenie mikroserwisów na własne konta AWS. Izolowanie usług na ich własnych kontach zapobiegnie niepotrzebnym sporom o zasoby. Prawda, będziesz mieć więcej kont do zarządzania, ale zaplanowane przepustowości staną się znacznie łatwiejsze do osiągnięcia, gdyż różne komponenty Twojego systemu nie będą konkurować między sobą w ramach tego samego limitu jednego konta AWS.
Usługa API Gateway ma miękki limit żądań na sekundę. Domyślnie jest to 10k i składają się na to wszystkie interfejsy API REST, HTTP i WebSocket na koncie w określonym regionie. Dlatego dobrze jest odizolować swoje usługi i własne API umieszczając je w oddzielnych kontach. Limit ten musi zostać zwiększony przy dużej skali.
Usługa Step Functions ma interesujący limit state transitions wynoszący 5k przejść stanu na sekundę we wszystkich standardowych maszynach stanu. Jeśli więc masz ponad 5000 standardowych przepływów pracy działających jednocześnie, oczekuj throttling`u , jeśli każdy z nich przechodzi w inny stan co sekundę.
Jeśli to możliwe, zmień standardowe maszyny stanu na ekspresowe. Są one przeznaczone dla dużych obciążeń przetwarzania zdarzeń i skalują się o rzędy wielkości wyżej niż standardowe. Nie ma limitu przejść stanu w przypadku ekspresowych maszyn stanów.
Jeśli nie można zmienić typu maszyny stanów, należy samodzielnie przechwytywać i ponawiać próby przejścia stanu w maszynach stanów.
Oczywiście aplikacja, która skaluje się do takiego poziomu, będzie kosztować znaczną ilość pieniędzy. Oznacza to, że należy wykorzystać każdą okazję, aby zoptymalizować wydajność aplikacji.
Jeśli to możliwe, łącz bezpośrednio usługi zamiast używać do tego Lambdy. Przełącz swoje funkcje, aby korzystać z architektury arm64. Stosuj batch`owe przetwarzanie, gdy tylko jest to możliwe.
Podsumowanie
Rozmiar ma znaczenie.
Ilość ruchu obsługiwanego przez Twoją aplikację ma bezpośredni wpływ na sposób zaprojektowania architektury. Stwórz architekturę pod skalę, którą będziesz miał w najbliższej przyszłości, a nie skalę, którą będziesz miał za 10 lat.
Serverless nie jest srebrną kulą. Nie rozwiązuje wszystkich naszych problemów tylko dlatego, że piszemy logikę biznesową w funkcji Lambda.
To, że usługi serverless mogą się skalować, nie oznacza, że będą się skalować.
Jako architekt rozwiązań Twoim zadaniem jest upewnienie się, że wszystkie komponenty aplikacji są zaprojektowane tak, aby skalować się razem. Nie chcesz, aby komponent na wejściu skalował się znacznie szybciej/wyżej niż komponent, który następnie przetwarzania te dane. To zbuduje stale rosnące zaległości w żądaniach, których nigdy nie będziesz w stanie skonsumować. Znajdź równowagę.
Obserwuj limity usług. Zaprojektuj aplikację, która samoistnie ponawia żądania. Zautomatyzuj wszystko. Wypatruj błędów i uchybień. Bez względu na skalę, musisz być na bieżąco z aplikacją i dokładnie wiedzieć, jak działa w dowolnym momencie. Pomoże Ci to wprowadzić odpowiednie modyfikacje (jeśli to konieczne) i dokonać optymalizacji, które zarówno zwiększą wydajność, jak i obniżą koszty.
Kiedy czujesz, że zbudowałeś aplikację, która skaluje się do pożądanego poziomu, wykonaj testy obciążeniowe. Upewnij się, że robi to, co powinna.
Powodzenia. Projektowanie aplikacji na dużą skalę to fajne i wyjątkowe wyzwanie. W niektórych przypadkach chodzi zarówno o infrastrukturę, jak i logikę biznesową.
Miłego kodowania!