W tym artykule opiszę jak pozbyłem się dwóch funkcji Lambda w moim procesie ładującym dane do jeziora danych.
Wszystko za sprawą zmiany ogłoszonej w październiku 2021, za sprawą której Step Functions otrzymało natywną integrację przez API z ponad 200 usługami AWS. Muszę przyznać, że czekałem na tę aktualizację już od wakacji, gdy mój TAM zdradził, że zespół Step Functions pracuje nad nowymi integracjami.
Co się zmieniło w Step Functions?
Pewnym preludium do ostatniej aktualizacji była dostępna już od dłuższego czasu nowa forma wywoływania funkcji Lambda. Różnice było widać tylko w języku definiującym maszynę stanów. W starej konfiguracji, wywołanie Lambdy definiowaliśmy tak:
1 | StateName: |
W nowej robimy to w następujący sposób:
1 | StateName: |
Na pierwszy rzut oka widać zmianę. Zamiast własnego zasobu podajemy uniwersalnego klienta w polu Resource, dopiero jemu podajemy nazwę naszej funkcji do uruchomienia jako parametr.
Ta zmiana dla nas - użytkowników - nie miała żadnego znaczenia, oba zapisy są równoważne. Domyślam się jednak, że stanowiła krok milowy na drodze do udostępnienia natywnej integracji Step Functions z AWS API pozostałych usług.
Od teraz mamy dostęp do 200 różnych integracji, które wywołujemy w taki sposób:
1 | StateName: |
W nowej robimy to w następujący sposób:
1 | StateName: |
Na pierwszy rzut oka widać zmianę. Zamiast własnego zasobu podajemy uniwersalnego klienta w polu Resource, dopiero jemu podajemy nazwę naszej funkcji do uruchomienia jako parametr.
Ta zmiana dla nas - użytkowników - nie miała żadnego znaczenia, oba zapisy są równoważne. Domyślam się jednak, że stanowiła krok milowy na drodze do udostępnienia natywnej integracji Step Functions z AWS API pozostałych usług.
Od teraz mamy dostęp do 200 różnych integracji, które wywołujemy w taki sposób:
1 | StateName: |
AWS SDK - człowiek czuje się jak w domu 😃
Tym sposobem możesz skopiować plik z S3 (arn:aws:states:::aws-sdk:s3:copyObject), uruchomić maszynę EC2 (arn:aws:states:::aws-sdk:ec2:startInstances), i tak dalej. Opcji jest multum.
Ale ile to wszystko kosztuje?
I tu jest największy bajer: nic nie kosztuje.
Powtarzam: jest za darmoszkę 😃
W sensie samo wywołanie API SDK (o ile jest darmowe, większość jest, tu się nic nie zmienia). Za samą maszynę stanu i działanie wywołanego serwisu oczywiście płacimy, jak dotychczas.
Skoro nic nie kosztuje, to warto zastąpić funkcje Lambda wywołujące inne serwisy natywną integracją. Dzięki czemu oszczędzimy na kosztach Lambdy (tak naprawdę to mniej niż groszowe koszty i w szerszym kontekście pomijalne), ale również na czasie implementacji funkcji.
No bo jak zawsze: brak kodu to najlepszy kod.
A ile to faktycznie trwa?
Ta oszczędność czasu na implementacji to przyznam Ci się szczerze nie jest taka oczywista. Gdy refaktoryzowałem dwie funkcje na natywne integracje, to zajęło mi to 3 godziny. W ciul czasu. No ale jak wszyscy wiemy:

Tak to wyglądało w moim wypadku, gdyż API AWS nie zwraca idealne na tacy tego, co byśmy sobie życzyli akurat w danym momencie. Zwracane wartości trzeba obrobić, co jest trudne, jak się nie ma funkcji Lambda do dyspozycji. I nie czytało się dokumentacji 🤣
Refaktoryzacja
W moim wypadku zamieniłem implementacje po lewej na tę po prawej. Przypominam, cały proces przetwarza dane i ładuje do Data Lake, stąd odwołania do serwisu Glue. W Twoim przypadku to może być dowolna inna usługa AWS.
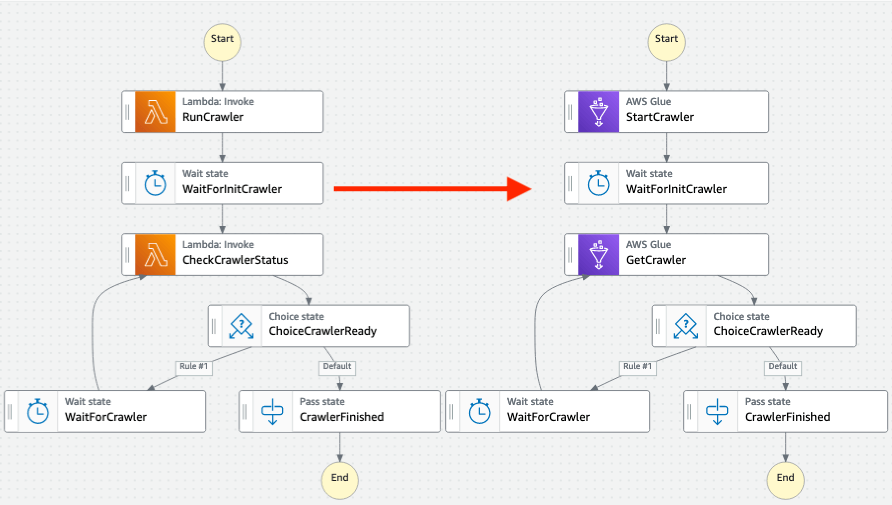
Cała maszyna stanów jest wywoływana z payloadem, w którym jest podana nazwa Glue Crawlera. Lambda oczekiwała zmiennej crawlerName, natomiast API StartCrawler potrzebuje Name.
To nie było jeszcze takie trudne do rozwiązania:
1 | StartCrawler: |
Natomiast dużym problem dla mnie było ogarnięcie danych wyjściowych z tego stanu, gdyż startCrawler nie zwraca żadnych danych, a domyślnie StepFunctions przekazuje do następnego kroku wynik aktualnego. Dwa kroki dalej GetCrawler też będzie potrzebował nazwę Crawlera, aby sprawdzić jego stan (czy jest uruchomiony albo zakończył działanie).
Problem rozwiązałem poprzez sięgnięcie do globalnego kontekstu wywołanej maszyny stanów oraz posłużenie się filtrem ResultSelector do zbudowania własnego obiektu na wyjściu ze stanu.
1 | StartCrawler: |
To tylko poglądowy przykład i nie uwzględnia obsługi błędów i mapowania ich na wyjściu ze stanu.
To spowodowało, że na wyjściu ze stanu miałem obiekt ze zmienną crawlerName. O to mi chodziło.
Następnym krokiem było pobranie aktualnego stanu Crawlera metodą GetCrawler w pętli, która trwa, dopóki nie zakończy on działania. Posłużyłem się tutaj podobnym rozwiązaniem jak wcześniej. Wartość state jest wykorzystywana przez warunek (Czy Crawler zakończył działanie?) w pętli, a crawlerName jest parametrem wejściowym dla kolejnego wywołania stanu GetCrawler. Crawler.State pochodzi z wyników zwróconych przez API getCrawler.
1 | ResultSelector: |
Czy było warto to zmieniać?
Oczywiście, że tak, mimo tego, iż kosztowo (w tym konkretnym przypadku) to nie było uzasadnione.
Po pierwsze brak kodu to najlepszy kod. Tutaj zastępujemy customowy kody Lambdy deklaratywną definicją maszyny stanów. To znaczy, że dowolna osoba na świecie znająca Step Functions zrozumie, jak to działa, bez zagłębiania się w nasz wspaniały kodzik Lambdy.
Po drugie ćwiczenie czyni mistrza. Ż̶o̶n̶g̶l̶o̶w̶a̶n̶i̶e̶ Mapowanie wartości na wyjściu jest trudne tylko na początku. Jak się ogarnie jak to działa, to dalej idzie dużo sprawniej. Mam nadzieję, że ten tekst pomoże Ci uniknąć wielu problemów, które ja napotkałem 🙂
Po trzecie natywne integracje, są na tyle wszechstronne, że od teraz praktycznie w każdej maszynie stanu będzie można z nich skorzystać, a to oznacza, że inwestycja w ich opanowanie na pewno się zwróci przy kolejnej implementacji.
Po czwarte, deklaratywny kod maszyny stanów jest łatwiejszy do ponownego użycia (copy paste) niż kod Lambdy.