Pracując w IT od lat wiem, że nie ma czegoś takiego jak silver bullet. Każde rozwiązanie ma swoje wady i zalety. Jakby tego było mało, często nie ma obiektywnej, z góry przyjętej, klasyfikacji, co jest wadą, a co zaletą. Przeważnie ocena zależy od konkretnej sytuacji i wymagań stawianych przed budowanym rozwiązaniem. Jak to mówią: context is a king!
Mimo uderzającej relatywności bijącej z powyższego wstępu chcę przedstawić Ci listę problemów z którymi prawie na pewno się spotkasz korzystając z architektury i technologii serverless. By przygotować ten materiał jak najbardziej rzetelnie i wielowymiarowo poprosiłem o wypowiedzi kilku rodzimych specjalistów od serverless, tak aby zbilansować moje subiektywne zdanie z doświadczeniem i wiedzą innych osób.
Mam nadzieję, że ta lista umożliwi Ci podjęcie świadomego wyboru czy serverless to jest coś z czym chcesz się zmierzyć i czy na pewno zalety przeważają nad wadami w Twojej opinii?
Uwaga: w tym artykule nie będę się mierzył z mitami i błędnymi przekonaniami funkcjonującymi w światku programistycznym. Zatem jeśli czegoś tu brakuje to albo w istocie nie jest problem albo jest na tyle błahe, że się nie załapało na tę listę 😉 Przykładem mitu jest rzekomo wyższa złożoność rozwiązań serverless w stosunku do klasycznych architektur - znakomicie z tym rozprawił się Yan Cui w swoim artykule Even simple serverless applications have complex architecture diagrams”, so what?
Problemy serverless
1. Złudna prostota funkcji Lambda
Każdy programista stawiając swoje pierwsze kroki w serverless ma już duży bagaż doświadczeń zdobytych na wcześniejszych projektach. Najczęściej oznacza to, że tworzył aplikacji w architekturze monolitów w ciężkich językach (Java czy C#). Oczywiście, część osób ma już duże doświadczenie w mikroserwisach, ale to nadal większe komponenty niż funkcje.
Przeskakując na serverless pisany w JavaScript czy Python łatwo zachłysnąć się wolnością oferowaną przez te technologie. Funkcje są na tyle małe i proste, a brak (wymuszania użycia) typów sprawiają razem, że wydaje się iż nie trzeba pamiętać o dobrych praktykach rzemiosła programistycznego.
 Nic bardziej mylnego! Świetnie tę kwestię podsumował programista oraz Cloud Architect Wojciech Dąbrowski w swojej wypowiedzi:
Nic bardziej mylnego! Świetnie tę kwestię podsumował programista oraz Cloud Architect Wojciech Dąbrowski w swojej wypowiedzi:
Częstą pułapką i pokusą w aplikacjach serverless jest swobodne podejście do jakości kodu i testów automatycznych. Tworząc jakieś rozwiązanie, szczególnie na etapie POC lub MVP, stosunkowo łatwo jest przeoczyć ten aspekt. Początkowy rozmiar kodu może być znacząco mniejszy niż w aplikacjach monolitycznych, czy nawet w mikroserwisach. To z kolei może podsunąć myśl, że nie ma sensu pisać do niego testów lub dbać o jego jakość. Moim zdaniem powinniśmy traktować kod stworzony w ramach aplikacji serverless z co najmniej taką samą troską. Pracując z takimi projektami, staram się pamiętać o testach automatycznych. Warto również zastosować na przykład architekturę heksagonalną - nawet w przypadku funkcji Lambda.
2. Testowanie
Zdecydowanie z testowaniem będziesz mieć problemy. Nie spotkałem się w swojej karierze z nikim kto by na to w serverless nie narzekał. Wręcz przeciwnie!
Bynajmniej nie oznacza to, że się nie da testować!
 Testowanie to standardowe wyzwanie przy pracy z aplikacjami klasy Serverless - mówi Wojciech Gawroński, główny architekt i CTO w firmie Pattern Match - wymaga zmiany nastawienia oraz poznania nowych wzorców architektonicznych (np. ports and adapters - znany również pod nazwą architektury heksagonalnej).
Testowanie to standardowe wyzwanie przy pracy z aplikacjami klasy Serverless - mówi Wojciech Gawroński, główny architekt i CTO w firmie Pattern Match - wymaga zmiany nastawienia oraz poznania nowych wzorców architektonicznych (np. ports and adapters - znany również pod nazwą architektury heksagonalnej).
Jednak same wzorce i style architektoniczne nie wystarczą. W pierwszej kolejności należy zrozumieć sedno problemu i zidentyfikować, co najbardziej się do niego przyczynia. Moim zdaniem głównym winowajcą jest fakt, że w architekturze serverless korzystamy z wielu gotowych usług, które rozdzielają nasz kod na małe części. Na przykład Lambda -> SNS -> Lambda -> DynamoDB -> Lambda -> SES (6 komponentów a kod mamy tylko w trzech z nich). Te fragmenty bez usług w chmurze nie mają większego sensu i po prostu nie działają. Proszę, nie zrozum mnie źle, wykorzystanie gotowych usług to równocześnie największa zaleta serverless, niestety utrudnia testowanie.
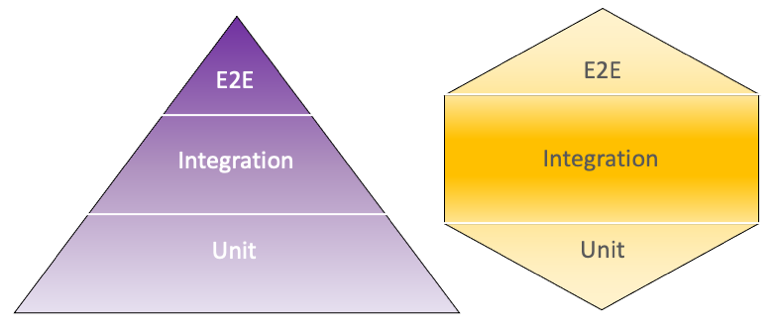
Na przestrzeni ostatnich dwóch lat można zauważyć intensywne działania społeczności serverless mające na celu ułatwienie testowania. Jeśli chodzi o design należy wymienić wykorzystanie wspomnianej już architektury heksagonalnej oraz na odejście od starej dobrej piramidy testów i zastąpienie jej bardziej nowoczesnym konceptem, który diametralnie zwiększa ilość zalecanych testów integracyjnych.
Na płaszczyźnie technicznej, pojawiło się wiele rozwiązań z których dość dużą popularność zyskały wszelkiego typu mocki - maszyny wirtualne uruchamiane w Dockerze na komputerze programisty emulujące prawdziwe usługi chmury AWS. Najbardziej znany jest tutaj localstack, którego użycie jest antywzorcem i zdecydowanie go Tobie odradzam!
To może być zaskakująca rada dlatego ją uzasadnię. Po pierwsze localstack to projekt open-source, który nie jest wspierany przez AWS i nie gwarantuje, że mocki usług będą sie zachowywały jak oryginały. Po drugie, używając tego typu rozwiązań nie jesteś w stanie przetestować dostępów opisanych rolami IAM, co w praktyce oznacza, że Twoje testy w żaden sposób nie gwarantują, że po deploymencie Twój kod będzie działać w chmurze! I wreszcie po trzecie użycie mocków i Dockera komplikuje środowisko deweloperskie (sam niejednokrotnie słyszałem jak ktoś spędził 2 dni na konfiguracji tego typu rozwiązań).
Zatem jak testować?
Należy pisać dużo testów integracyjnych, które używają rzeczywistych zasobów w chmurze. Projektując aplikację w stylu architektury heksagonalnej jest to względnie proste i dosyć łatwo napisać kod który komunikuje się z usługami w AWS (czy dowolnej innej chmury) z komputera programisty. Co więcej, w ten sposób można również testować przywileje funkcji Lambda opisane rolami IAM - tego żaden mock, ani Docker nie umożliwia.
3. Długi feedback loop - kiepski workflow programisty
Workflow wielu programistów w serverless jest nieefektywny:
- Piszesz kod
- Deployujesz do chmury
- Odpalasz Lambdę… i nie działa.
- Wracasz do punku 1.
Po paru takich iteracjach w końcu masz działający kod, ale to zajmuje zdecydowanie zbyt dużo czasu.
Proces deploymentu funkcji trwa około minuty, jej uruchomienie kolejne kilkanaście sekund - razem to powoduje, że feedback loop jest długi, a Ty dostajesz informację zwrotną czy coś działa czy nie po dłuższej chwili. Na tyle długiej, że często coś zdąży wybić Cię z flow programistycznego.
Oczywiście to się bezpośrednio wiąże i jest efektem braku testów o czym już pisałem.
4. Ciężko znaleźć przyczynę błędów
Nawet w stosunkowo prostych mikroserwisach zbudowanych w oparciu o serverless używamy minimum kilku usług, które to aby zostać poprawnie skonfigurowane na etapie deploymentu tworzą setki zasobów w chmurze (Resources w rozumieniu elementów stacków CloudFormation). Oczywiście, przytłaczająca większość jest generowana dla nas automatycznie ,ale to pokazuje ile rzeczy musi ze sobą współgrać, aby system działał poprawnie.
Mnogość zasobów po stronie infrastruktury oraz fakt, że serverless to są systemy rozproszone powodują, że debugowanie aplikacji jest pracochłonne i często trudne.
Odpowiedzią na ten problem jest obserwowalność, czyli logowanie, monitoring i śledzenie. Użycie dedykowanych rozwiązań (w tym komercyjnych) w celu monitoringu i śledzenia tego jak informacje przepływają między komponentami naszego rozwiązania jest jak najbardziej zalecane, szczególnie w systemach produkcyjnych o dużym wolumenie transakcji.
Jeśli kiedykolwiek słyszałeś o NoOPS w kontekście serverless to jest to po prostu nieprawda.
5. Mnogość opcji wyboru - względność architektury
Skoro już wspomniałem o wolumenie transakcji to kontynuujmy ten temat. Jest to krytyczny współczynnik, który powinien ostateczne decydować przy wyborze konkretnych usług, a więc i samej architektury. Dzieje się tak dlatego, ponieważ różne usługi AWS możemy użyć do realizacji tego samego zadania i dopóki nie weźmiemy pod uwagę wolumenu wybór często będzie kwestią gustu.
Za przykład niech posłużą następujące usługi: SNS, SQS, EventBridge oraz Kinesis. Wszystkie służą do przesyłania wiadomości, każda z nich ma inne limity oraz inną charakterystykę kosztów uzależnioną właśnie od wolumenu.
Przykład: Jeśli byśmy mieli wysyłać jedną wiadomość wielkości 1KB, co jedną sekundę przez cały miesiąc to SNS by nas kosztował 1,296 USD (1 dolar 29 centów), EventBridge 2,592 USD, a Kinesis aż 10,836 USD. Różnica, aż o jeden rząd! Jednak przy skali 1000 wiadomości na sekundę następuje grube przetasowanie. SNS kosztuje 1296,00 USD, EventBridge 2592,00 USD, a Kinesis tylko 47,09 USD. (Źródło: Yan Cui)
To powoduje, że trudno jest wybrać optymalną architekturę.
Patrząc na ten problem od innej strony, można powiedzieć, że nawet osoby ze sporym doświadczeniem, zdobytym na wielu projektach serverless o niskich wolumenach mogą być zaskoczone, że ich sprawdzone wzorce nagle przestają być najlepszym możliwym rozwiązaniem.
Nawet pomijając aspekt kosztów, w końcu nie każdy system przetwarza miliony transakcji dziennie, projektowanie może się okazać wyzwaniem. Mnogość opcji i trudność wyboru między nimi, zdecydowanie często przewijała się w wypowiedziach moich rozmówców.

Tomasz Breś, AWS Cloud Architect w firmie TT PSC, zilustrował to następującym przykładem ze swojego projektu:
Przy przetwarzaniu event based trafiliśmy na problem różnych poziomów konkurencyjności dla różnych usług AWS. Np. S3 -> S3 Event -> Lambda (konkurencyjność 1000) Przy załadowaniu 300 tys. Plików Lambda nie wyrabia Rozwiązanie: SQS Np. S3 -> S3 Event -> SQS -> Lambda Problem zostaje, jeżeli ta Lambda uruchamia np. GlueJob (konkurencyjność 70) Np. S3 -> S3 Event -> SQS -> Lambda -> GlueJob Wiadomości piętrzą się na kolejce, gdy Lambda próbuje uruchomić GlueJoba dostając w odpowiedzi błąd konkurencyjności. W efekcie przepustowość całego rozwiązania jest ograniczona do 70 równoległych procesów na raz. Rozwiązanie: Użycie EFS w Lambdzie do załadowania wymaganych bibliotek, które były za duże do standardowego (250MB) rozmiaru Lambdy i w ten sposób pominięcie wąskiego gardła (Glue Job).

Z problemami podobnej natury niejednokrotnie mierzył się Karol Junde, VP i CTO w firmie Chaos Gears, który przedstawił następujące alternatywy do wyboru:
29 sekundowy timeout dla wszystkich rodzajów integracji API Gateway z usługami AWS może wprowadzać delikatne konsternacje. Rozwiązania które najczęściej stosujemy to połączenie API Gateway z funkcją Lambda (nazywamy ją “forwarderem”), której jedynym zadaniem jest jak najszybsze odebranie eventu, przekazanie go dalej do SNS(model pub-sub), SQS lub ostatnio do EventBridge oraz oczywiście zwrócenie odpowiedzi. W przypadku forwardera ważnym elementem jest zrozumienie paradygmatu “concurrency” dla funkcji Lambda. Druga metoda to integracja API Gateway bezpośrednio z SQS i tutaj dochodzimy do scenariusza “webhooks”, gdzie user uderza z request do API Gateway, dostaje odpowiedź o przyjęciu request, a następnie backend w postaci API Gateway + SQS + Lambda + SNS zwraca mu odpowiedź w momencie kiedy request został obsłużony.
Myślę, że powyższe przykłady pokazują, że nawet doświadczonym inżynierom - a może przede wszystkim im, gdyż znają usługi na wylot - czasem trudno jest wybrać tę jedną, ostateczną, najlepszą architekturę.
6. Prędzej czy później musisz skorzystać z serwerowych rozwiązań!
Brzmi jak herezja!
Nie chodzi mi o to, że każdy jeden projekt będzie do tego zmuszony. Bardziej o to, że Ty jako programista w którymś z kolei projekcie będziesz musiał skorzystać z usług serverFULL - wtedy poczujesz jak wielki overhead generują i dlaczego serverless jest wspaniały! 😉
Ich konfiguracja jest czasochłonna i konieczna wszędzie tam gdzie będziesz musiał sie zintegrować z relacyjna bazą danych (RDS) lub podłączyć dysk sieciowy (EFS) do funkcji Lambda. To tylko dwie z szerszej grupy sytuacji gdzie będziesz musiał skorzystać z VPC. I o ile w przypadku RDS można zrzucić winę na integrację z legacy app to w przypadku EFS już tego tak się uzasadnić nie da (ile z tym zabawy opisałem tutaj).
Poza dodatkową, konieczną pracą niezbędną do skonfigurowania i użycia tych usług należy też pamiętać, że serwerowe usługi zupełnie inaczej się skalują niż te serverless i często wymagają daleko posuniętych działań mających na celu ich ochronę przed gwałtownymi peakami, które mogłyby - mówiąc kolokwialnie - je zarżnąć.
7. Dziury funkcjonalne w AWS
Po kilku latach pracy z AWS nabierasz doświadczenia i rutyny. Aplikacje serverless projektujesz w głowie prawie natychmiast po tym jak usłyszysz nowe wymagania od swojego szefa.
Siadasz do komputera i implementujesz. I tak po prostu jest!
Z drobnym ale.
Myśląc na wysokim poziomie zapominasz, że usługa A nie integruje się bezpośrednio z usługą B. Tam gdzie byłeś pewien, że No przecież niemożliwe, żeby AWS tego nie zrobił okazuje się, że jednak możliwe.
Jest nawet taki hashtag na Twitterze #AwsWhishList - to oczywiście dotyczy całej chmury, a nie tylko usług serverless ale w obszarze Lambdy nadal jest parę rzeczy które mogłyby być. 🙂
Przykłady? Proszę bardzo: Amazon DynamoDB Streams nie pozwala ustawić SQS jako celu. Eventy S3 nie mogą się nakładać na siebie. Lambda Destinations działa tylko przy asynchronicznym wywołaniu funkcji. Podobnym spostrzeżeniem podzielił się wspomniany już Wojciech Gawroński:
Pod powierzchnią czają się problemy - przykład: S3 Event Notifications, które świetnie pasują do wielu zastosowań, ale nie mają żadnych gwarancji dot. kolejności, gwarancji dostarczania i czasu wysyłki - co ma znaczenie dla niektórych przypadków użycia. Jedynym rozwiązaniem w takim przypadku jest nauka i eksperymentowanie (np. poprzez proof of concept), tak aby poznać te rozwiązania w praktycznym wydaniu i poznać ich wady/zalety.
Trzeba tutaj jednak wyraźnie zaznaczyć, że ilość pracy i zasobów inwestowana przez AWS w usługi serverless, z Lambdą na czele, jest ogromna i z roku na rok, coraz prościej, łatwiej i przyjemniej budować własne rozwiązania korzystając z tych nowych funkcjonalności.
8. Panta rhei
I płynnie przechodzimy do ostatniego filozoficznego problemu. Wszystko płynie, a w AWS to płynie w oszałamiającym tempie. Prędkość z jaką się rozwija ekosystem Lambdy oraz inne usługi serverless powoduje, że co pół roku, a już na pewno po każdym re:Invent nasze rozwiązania można gruntownie przebudować! 😉
Wyobrażam sobie, że niezmiernie ciężko byłoby komukolwiek wrócić do projektowania rozwiązań serverless po dwuletniej przerwie. Trzeba być na bieżąco. Usprawnienia są czasem na tyle duże, że coś co kiedyś było uważane za best practice dziś jest antywzorcem (np. grzanie funkcji Lambda, aby uniknąć cold startów).
Ciągłe zmiany i wspomniana powyżej względność architektury skutkują stosunkowo małą ilością sztampowych rozwiązań i najlepszych praktyk. W rezultacie na projektantach i architektach spoczywa ciężar przygotowania rozwiązania do którego mają pełne zaufanie, że jest najlepszym z wielu zmieniających się alternatyw. To niełatwe zadanie wymaga dużej wiedzy oraz pewności siebie.
Podsumowanie
Mam wielką nadzieję, że powyższa lista nie zniechęci Cię do serverless. Jest to wspaniała technologia, która oferuje bardzo wiele (o czym niejednokrotnie pisałem) i praca z nią to dla mnie osobiście czysta frajda. 😀
Nie ma rzeczy idealnych, a te problemy potraktuj jako wyzwania i po prostu się do nich przygotuj, albowiem na pewno będziesz musiał się z nimi zmierzyć. Teraz już wiesz 😉